Understanding the cost of software
Software is expensive. The only way to succeed is to understand the cost structure, and trade-offs involved.

The standard cliché in our industry is that software projects always take twice as long, and cost twice as much. Of the two factors, however, it's the financial one that does the most damage. Usually, timing does little damage in itself, other than making a company run out of money.
Without exaggeration, none of the companies I have worked with had a good understanding of how much a proposed software project would cost. Similarly, most of the external companies I have been exposed to seem to miss that understanding. Companies that produce bespoke software on a contract basis tend to be better than average, but even they do quite poorly, and often struggle with profitability. Part of the reason is, of course, the unpredictability of software engineering itself, but it is only part of the story. There seems to be a significant amount of concrete reluctance to think deeply about the costs of software, and instead people rely on “gut feeling” and extraordinary margins to try to make the business work. In this post, I will attempt to lay out the major components of the cost of modern day software. The goal is to make the thinking around software costs somewhat more organized, rather than create a template for estimating the total cost of the project. This will not only help reduce the disconnect between estimates and actual cost, but also help make better decisions when thinking about design choices that involve trading off some costs against others.
Before we dive into the cost structure, however, I want to cover one fundamental axiom that seems to be hard to accept for a lot of professionals: software is expensive! There is a surprising number of people in the industry, and even more in the sectors from where our customers come, who think that software is cheap. The reality is that writing software to accomplish a particular task is one of the most expensive ways to accomplish it! The only reason why software ever makes sense, is because the cost of copying software is practically zero, so in cases where you can can have enormous numbers of people doing the same task, you can amortize the cost to the point where it pays off. Think of an XML editor, for example: I know of no developer that would attempt to write one for his own use only, no matter how much he or she works with XML. Almost all the good XML editors are commercial, and their cost is covered by the license fees paid by millions of people. This idea, that software only makes sense commercially when targeted at a large number of users will steer most of the points we will discuss in the rest of the article.
Putting the software together
When discussing software costs, most people tend to think only of the cost of developing the product, and occasionally include something for the cost of operating the infrastructure on which it runs. Needless to say this picture is overly simplified and does not accurately reflect even the costs of putting the software together, let alone the Total Cost of Ownership (TCO). In this section we will focus on the costs of putting the software together, from inception to production.
Going back to our axiom from above, if we want our software to be commercially successful, we need to amortize the cost over a wide user base. Any piece of software will satisfy the needs of a portion of the Total Addressable Market (TAM), but not all of it. This brings up the first of the cost trade-offs: we can increase the percentage of the TAM that we capture as a potential user base by adding more features, but this will also increase the cost. Alternatively, we can reduce the cost by excluding features, but that reduces our potential user base. In reality, the relationship between feature cost and percentage of TAM covered is strongly non-linear, and the percentage asymptotically approaches 100% as the cost of features approaches infinity.
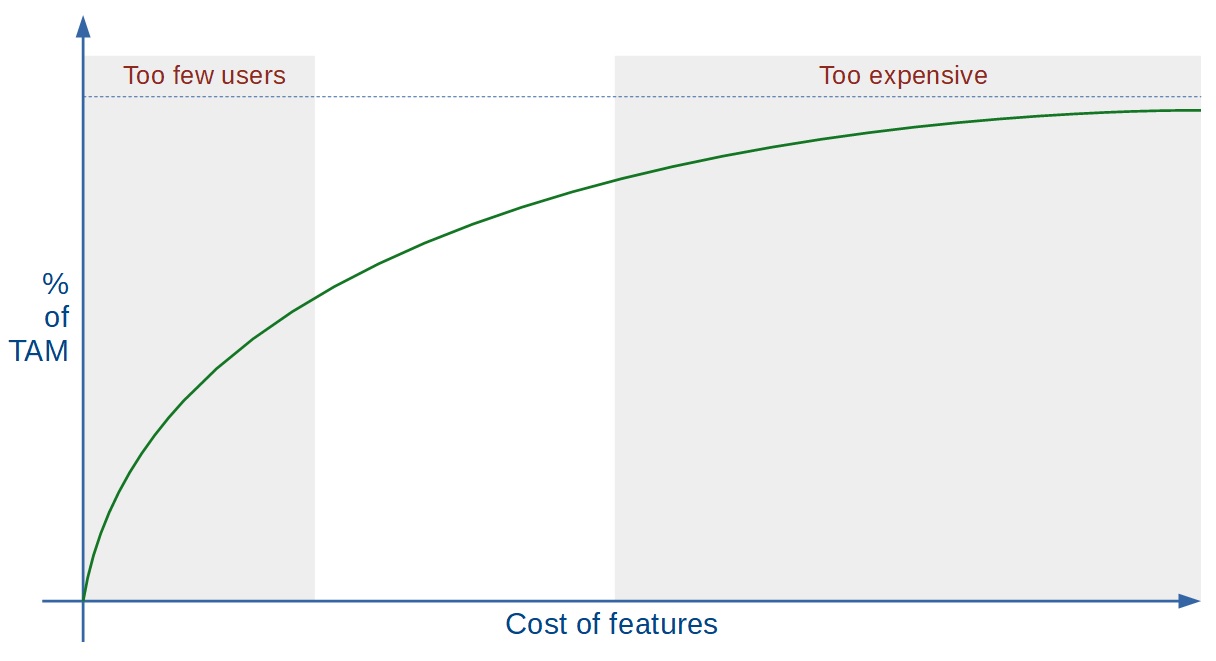
Feature cost and % of TAM covered
Most of us know this as the “80 / 20 Rule”, but I think the rule formulation lacks the sophistication to enable trade-off decisions. The important thing to note is that a large portion of the space on this graph is not commercially viable: the part of the graph to the left has too few users to be able to amortize the cost of the corresponding features, whereas the part to the right is simply too expensive. The actual portion of the graph which is viable is small enough, that it is unlikely a software product will land in it without careful design. This brings up the first, and most-often forgotten, component of the cost: Product Definition. For software distributed to multiple customers (i.e., all non-bespoke software), an organized product definition effort is not only an indispensable effort, but one that can be fairly complicated. It will generally involve significant market and product research, as well as deep dives with a significant number of potential customers to gather the high-level requirements. Note that, as is the case with development, it requires highly specialized and fairly expensive talent. Except when done superficially, it is certainly comparable to the costs associated with the design effort behind the software. Realistically, except for trivial products, this will be anywhere from many man-months to man-years worth of effort. One thing worth noting is that for bespoke software built on a contract basis, it is often assumed that this cost has already been covered by the customer and can be safely ignored. My personal experience, however, is that this is only partially true. Ideally, the customer has a decent idea of what features he or she would like, but in reality they do not understand the cost of those features well. The end result is that, for bespoke software, the equivalent cost manifests itself as two alternative costs:
- the pre-sales cost of competitive research, RFIs (Request For Information), and determining what restrictions and assumptions to put in the proposal when responding to an RFP (Request For Proposal)
- the cost of refining and renegotiating some of the requirements during the Business Analysis phase of the project, once the cost of the relevant features becomes clearer.
The next major component is the cost of designing the software. Generally this will have three sub-components:
- System Architecture: as part of this effort, one or more architects will break the system down into its major components, decide on the technologies to use, determine the principles and design patterns to use, and document all of the above decisions.
- Information Architecture: one or more UX and Design specialists will determine the basics principles governing the design of the user interface, create the fundamental elements of the UI, create style guides and samples, and document all of the decisions.
- Epics break down and basic UI flow: a Product Owner and one or more designers will together try to break up the functionality into modules / epics / flows, and determine the basic interactions with the end user. This is not the same as the definition of the actual user stories and screens, which will be performed as part of the implementation.
In general, there is certain amount of latitude as to how much effort a team wants to invest in design, but there is a minimum amount below which the project becomes too risky, and this minimum tends to be quite significant. In my experience, the sweet spot tends to be roughly equal to a third of the effort required for development, testing, and debugging.
The next cost component is implementation setup. This is often assumed to be trivial, and often ignored, but in reality tends to be quite significant. During this phase, a team will set up the basic infrastructure they need for the actual implementation phase. The local development environments need to be set up, including installing all the tools, libraries, and middleware needed for development. CI/CD Pipelines will be set up, along with the associated test environments. In addition, the design team will need to set up templates, as well as the shared artifacts (e.g. stylesheets and basic static content such as error pages). The PO will have to set up a backlog in the appropriate tool, and initialize it with at least the epics (although I would generally recommend that the backlog should contain enough broken down stories to fill approximately two sprints before implementation gets underway). In addition, there is a significant organizational setup that needs to happen, such as setting up the rituals, agreeing on a Definition of Done, and putting in place the collaboration infrastructure that the team will need. It's easy to underestimate the effort of setting all of this up, but it can add up to a very significant fraction of implementation. Popular wisdom suggests that this should be included in a “Sprint 0”, but my experience has been that is not sufficient, and the effort lingers on through quite a few of the subsequent sprints. The reason why it is important to understand this component, however, has less to do with the direct cost, and more to do with the indirect costs of doing it poorly. The temptation is always there to under-invest in this early phase, but the costs are multiplied by the entire lifetime of the software, and can therefore be substantially more than the required investment. The easiest example to explain, is that of CI/CD pipelines: a team could probably shave a week or two by not investing strongly in their pipelines, but this will slow them down on a daily basis over the entire lifetime of the product, which may be over a decade. Even as little as a 5% loss of efficiency comes out to 6 team-months of effort over a decade. The tendency to under-invest in setup is significantly higher in projects that are preceded by a prototype or PoC (Proof of Concept). It hardly seems worth it to expend the effort for a PoC or prototype, so the team puts together a quick and dirty setup, investing as little as possible. However, when the implementation of the full product begins, very few teams have the discipline to go back and re-do their setup.
The biggest component in putting the software together is, of course, implementation. This is what most people have in mind when they talk about the cost of software, but as we have shown already, this is but one component of the total cost. As we shall see in the next section, implementation is not even the most significant portion of the cost. Either way, this activity in itself has a significant amount of internal structure to it. It would be naive to think of this as simply “writing the code” (or more precisely, producing the source artifacts that will eventually make up the software). As it turns out, writing the code (including the automated tests), is only about one third of the effort of implementation. Most of the rest is debugging. This brings up a number of cost trade-offs into play. First of all, the design of the code itself, as well as the processes followed can have a significant impact. An example of a design trade-off is whether you are using technologies to enhance observability (e.g. Zipkin), or how extensive your logging is. An example of the processes, is whether you have guards in place (e.g. as part of the CI/CD pipeline) to catch code-smells and other code deficiencies on the local development machine where they are introduced, as opposed to making it into the general code-base and having to be debugged by someone other than the person that introduced them. You can trade off investment in making the code more testable and easier to debug, against the cost of the actual debugging. Since the cost of debugging is dominant, I tend to favor investing in lowering it, but at the end it is a matter to be decided within the team. An additional implementation cost is the cost of learning, especially that of learning new technologies and tooling. Imagine that you are using Zipkin for the first time. There will be a cost associated with learning the design patterns associated with using the framework. There will also be additional costs in learning how to use the produced information to actually extract value from it. All of this learning generally occurs during implementation, as the team actually gets hands-on, but it is often completely missed in the original estimates (teams are generally pretty good about catching this during backlog refinement, but rarely is it part of the high-level estimates during the project planning phase).
Additionally, there are certain costs, generally incurred at the end of development, that are very much part of implementation. The most commonly included one is the cost of “stabilization”, generally understood as the removal of the surge of bugs discovered after the code is complete. Note that this is not based on the assumption that testing and bug-fixing happens at the end; even with testing and bug-fixing as part of the sprints, there is always a set of bugs that, due to prioritization, linger at the bottom of the backlog, or are not discovered until everything is put together. I am surprised, nonetheless, at how often even teams that are well-aware of the need for stabilization fail to plan and account for it. Above and beyond stabilization, however, there are two other significant efforts that should be included: security testing, and performance characterization and optimization. It is absolutely amazing how rare it is for teams to plan and account for security testing, despite the fact that, for any reasonable externally accessible software, it is a must-have. Penetration testing should really be performed by an external team, and can usually come with a five or six digit price-tag (not including the cost of addressing any vulnerabilities found). Performance characterization and optimization is not quite as expensive, but suffers from a tendency to be ignored in the rush to get to production. This is an implicit trade-off: the team saves the time and money required to do the characterization and optimization, but increases the costs of the software in production (more in the next section). Since the decision is made implicitly, it is often incorrect and costly.
The final cost of implementation is getting to production. This should also not be underestimated: form the amount of time it takes to actually deploy (the first deployment never goes quite right), to possible disruption to other software running on the same infrastructure, the cost of deploying to production can actually add up to something quite significant. Once again, there are trade-offs to consider. For example, in the case of SaaS, a team could trade off an investment in building production tooling against the cost of future deployments (part of the cost of operating the software). There is also a certain cost of learning associated with making the transition to production. For one thing, teams never seem to prepare for the fact that, in production, they should minimize or eliminate downtime, and cannot allow any data loss. Until the transition to production, the teams use processes that may cause downtime and data loss - in fact, they often blow away the entire test system as part of deploying a new version of the software. This means that any deployment experience they have acquired is not applicable to production scenarios, and they must acquire all relevant learnings as part of that transition to production.
The cost of Agility
A special cost worth discussing in detail is the cost of agility. Agile has many purposes (not all of which are compatible with each other), but when most people speak of Agile software development, they generally think of the idea of iterating over small increments of the software to improve usability. This process, naturally, is associated with a significant cost: the same functionality is re-worked multiple times in order to optimize problem-solution fit and usability. Note that this is once again a trade-off: investing in the re-work can reduce the support cost during the operating phase of the life-cycle. Alternatively or in addition, a team can invest in the re-work to increase the revenue by increasing user adoption, and/or increasing the price premium the company can charge for the software. Note that this cost is significant - most of the design of the software (if not the functionality) will generally get re-worked at least once (and, occasionally, multiple times), effectively doubling the cost. Of course, there is a whole spectrum of possibilities between re-working nothing and re-working everything, but in order to maximize the net gain, the decisions must be taken purposefully and with due consideration.
Costs of software in operation
While the software is in operation (during the useful part of the life-cycle), it entails three major cost components.
Maintenance Costs
Once the software is in operation, it doesn't stop evolving. In fact, more often than not, the development activities continue at the same or even higher pace. There is, of course, a continuous need to fix bugs. However, in addition to bug fixing, there is continuous development activity to update the functionality to meet user expectations, and to accommodate user feedback. Any such update to functionality that cannot be billed on its own, is simply accounted under maintenance. I was once even asked (by my CEO nonetheless) if we could skip the maintenance cost by simply no longer making updates to the functionality: the answer is, of course, no. First of all, the stream of bugs will still come in, and while you might reduce the number you take on, some bugs you simply can't decline to fix (especially security related bugs). In addition, every piece of third-party software you used in building your software (down to, and including, the operating system) will continue evolving and you need to keep updating them (once again, if nothing else, for security reasons). Some of these updates will break your implementation, so you will need to debug it, fix the implementation, test the fixes, and re-deploy. At any rate, it is unrealistic to expect to not invest in maintenance in an operational product - the only time it makes sense is if usage is dwindling rapidly (i.e., the product is in a death spiral).
The most important thing to note is how significant the maintenance cost is. In general, it is very rare for the development team to decrease in size after the software is in operation (with bespoke software being the notable exception). On average, the team size actually increases, often to a multiple of the team that originally put the software together (think Twitter, but there are countless other examples). Add to this the fact the the operation phase is often much longer than the development phase - a successful piece of software may have taken a year or two to develop, but with continuous updates may live in operation for over a decade. These two factors together mean that the maintenance costs are bigger than the development costs by at least an order of magnitude, and in some cases by two! If you are lucky, the revenue has increased enough in the meantime to cover the increased cost, but, in reality, luck is not a strategy, and the cost is rarely included in the business case. The only reason why this occasionally works is because in a few cases the user base and the associated revenue increases by an even bigger factor than the cost, and has creates an extraordinary margin that can cover the cost. In most cases, however, the user base does not show this extraordinary scaling and the costs dominate the issue of profitability.
Significantly, there are a number of very important trade-offs between costs in development and costs in maintenance. One of the most obvious is the issue of technical debt. In general, shortcuts during development tend to manifest themselves as maintenance cost in production. The cost can be either direct, for example, a large incidence rate of bugs associated with the modules that have a high technical debt, or indirect, for example a reduced ability to modify the software because of stability or code comprehension issues. I believe that the issue of technical debt is fairly well understood, and what is lacking is simply the required discipline, so I will not cover it in more depth here.
Another significant trade-off is the presence or absence of technology to enhance observability and the ability to debug the software. For the bug fixing portion of maintenance, the bulk of the activities focus on debugging and understanding what went wrong. If the team invested in observability technology during development, this cost is reduced during maintenance. And since the cost of maintenance is so much bigger than the cost of development, the ROI will more often than not be positive (although that does not automatically mean that the investment makes sense). It is also worth noting that debugging in production is significantly more difficult than debugging in development. To begin with, engineers are heavily restricted as to what they can do with a production environment (for example, it is almost never acceptable to attach a debugger to a production environment). In addition, because of the scale of use and the inherent concurrency of production, it tends to uncover issues that are hard to reproduce, either because they have inherently a low probability of happening, or because the are the result of race conditions. The hardest part of fixing such issues is reproducing them in the first place, which is greatly aided by observability technology.
Also important, is the trade-off between investing in test automation during development. Test automation has two beneficial effects. First of all, as long as it is used by each developer when modifying the code, it tends to pinpoint the exact cause of broken functionality, reducing the debugging costs dramatically. If the tests passed before I made a modification, but fail after my modification, then I know that my changes have to be responsible for the fault, and I can narrow down my debugging effort very quickly. The second benefit is that it reduces the code comprehension effort required to make modifications. If I don't have faith in my test automation, I will invest a lot of time to make sure I understand the full impact of any change I am about to make, before I actually start modifying the code. If, on the other hand, I am confident that my test automation will catch any break in functionality, I will invest significantly less time up front, and only delve deep if the tests actually fail.
Support Costs
Support costs are primarily dictated by two factors:
- How easy the product is to use
- How stable the product is
The actual costs can vary over a very wide range depending on those two factors. Products that are stable and easy to use require very little support (do you even know how to contact support for Android?). On the other hand, products that are counterintuitive, or somewhat unstable, tend to require large support teams. The primary cost component for support tends to be the personnel cost for the actual support representatives (the people fielding the calls, or answering the customer emails), as well as the costs of any tooling they use (phones, ticketing system, etc.). In unstable products, there is also a significant overhead incurred on the engineering team, as they need to investigate a lot of the issues that come from support (we include the cost of fixing the issues in maintenance, instead of support).
The most interesting trade-off is the one between support costs and usability. As you will recall, we specifically highlighted the cost of agility during our discussion of development calls. That cost, however, can be traded off against support cost. Investing in higher usability will directly reduce support cost, and will almost certainly have a further beneficial effect, by increasing the user base or price premium.
One point worth pointing out: customer configurability in the product acts as a significant cost multiplier in support. Whenever something goes wrong, it is difficult for the support representative to understand whether this is an issue of the user not understanding how to use the software correctly, a bug in the software itself, or something caused by the customer configuration. Resolving this can be complicated and takes up a lot of support representative time. It is also worth noting that if the behavior of the software can be significantly altered by the customer using configuration, usability will almost invariably suffer. If nothing else, the customer employee that is tasked with maintaining the configuration is almost certainly not versed in the concepts of usability.
A special note regarding the cost of personnel: for globally distributed software, support generally tends to be 24 / 7. This implies, either the use of off-hour shifts which require a corresponding premium, or the use of multiple sites around the globe, which imply a significant cost overhead. There is also an indirect cost, associated with the need for support representatives to communicate with engineering for a significant portion of the issues. While support tends to be 24 / 7, engineering is generally limited to normal business hours in one or a couple of locations, meaning that the process for resolving issues that come in off-hours will take longer and have reduced efficiency. It is important to make sure you take this into account both in terms of the cost, as well as in terms of the impact to the SLAs.
The trade-off involving stability is similar to the case of maintenance - there is little to add here.
Operating Costs
Operation costs are the costs of keeping the software running, at the scale and in the manner required to serve the needs of the customers. It includes the cost of hardware to run the software on (typically the datacenter cost, or cloud provider cost), the cost of the system engineers that operate the software , the cost of licensed software and middleware incorporated into the product (e.g., commercial databases, integration engines, ESBs, etc.), the cost of software used for operation purposes (e.g. monitoring software, backup software), the cost of external services (e.g., penetration testing, 24 / 7 monitoring), and miscellaneous costs such as SSL certificates , etc. For any significant piece of software, operating costs can easily run into the millions, especially in SaaS products.
Note that for almost all operating costs, there is a direct trade-off between the specific operating costs and the cost of development. Consider, for example, the case of performance characterization and optimization mentioned earlier. If, as suggested before, the team chose to defer investment in performance during the development phase, they may find that they need to compensate by using more hardware, or more expensive hardware, increasing software costs. If the team chose to skip performance characterization during development, they may find that the application suffers occasional degradation in performance, requiring remedies to be paid to the customers because the performance SLAs are not met on occasion.
Similarly, if technologies were chosen during development that have fairly high licensing costs, this will manifest itself as a significant operating costs during the operating phase. Conversely, if technologies were chosen that are low cost but not gentle on resources, this will reduce the licensing costs but increase the hardware costs.
In general, it is often a bit complicated to estimate the exact impact of design choices on operation costs (even though a rough estimate should be easy to generate). Teams often take their best guess, and then simply tolerate the operating costs as they show up once they are in production. However, there is no reason for this to be the case: once the teams have the actual operating cost figures from production, they could revisit some of the design choices and re-engineer the software to reduce some of the costs. While it is true that the costs of re-engineering could be substantial, the operating costs tend to be so high, and are incurred over such a length of time, that large investments could easily be justified. In general I would recommend that teams re-examine their operating costs on a regular basis and evaluate if it makes sense to re-engineer the software to reduce the cost.
As in the case of support, Operations needs to be available 24 / 7, albeit at very reduced levels off-hours. Often, and for various reasons, it is undesirable to have the system engineers spread in multiple locations. It is much more typical to have on-call duty within the members of a group located in a single location. This not only requires a premium (on-call hours are usually paid at a different rate), but also means that there is a minimum critical mass of people required to create an effective rotation.
Cost of sun-downing software
The final cost, is the cost of decommissioning the software and ceasing operations. This cost is almost universally ignored, but I would like to make the case that it shouldn't be. The software may have reached the end of its useful lifetime, but the data it contains almost certainly hasn't. Imagine that the software in question is an accounting system: it is almost certain that the customer will want to retain the data, not only for archival purposes but even in a operational form (e.g., to file the taxes for the upcoming fiscal year, or to be able to perform the end-of-year audit). If, as the producer of the software, your company is ceasing to exist, perhaps you don't care that much. But in all other scenarios, you will want to enable the customer to retain his data. This will incur a certain cost, which may be quite significant if the software was not designed with End Of Life (EOL) in mind. There may even be a double hit to the company, if the customer is being migrated to a different product from the same company, or to a product from an acquiring company: one must add to the cost of extracting the data from the EOL system, the cost of importing the data to the new system. Additional costs may be required if you need to provide a replacement product or service, or a remediation payment to the customer, but those situations are rare.
in general, a little bit of foresight with regards to EOL can significantly reduce the costs when the time comes. A well-designed data schema and a couple of extraction interfaces is almost all that is needed. The investment can even be deferred until the later stages of the product's life-cycle.
Summing it up
With so much detail to consider, it is hard to escape the feeling that the big picture will invariably get lost. I, therefore, wanted a way to bring it back to life by putting everything together on one diagram (area is proportional to cost):
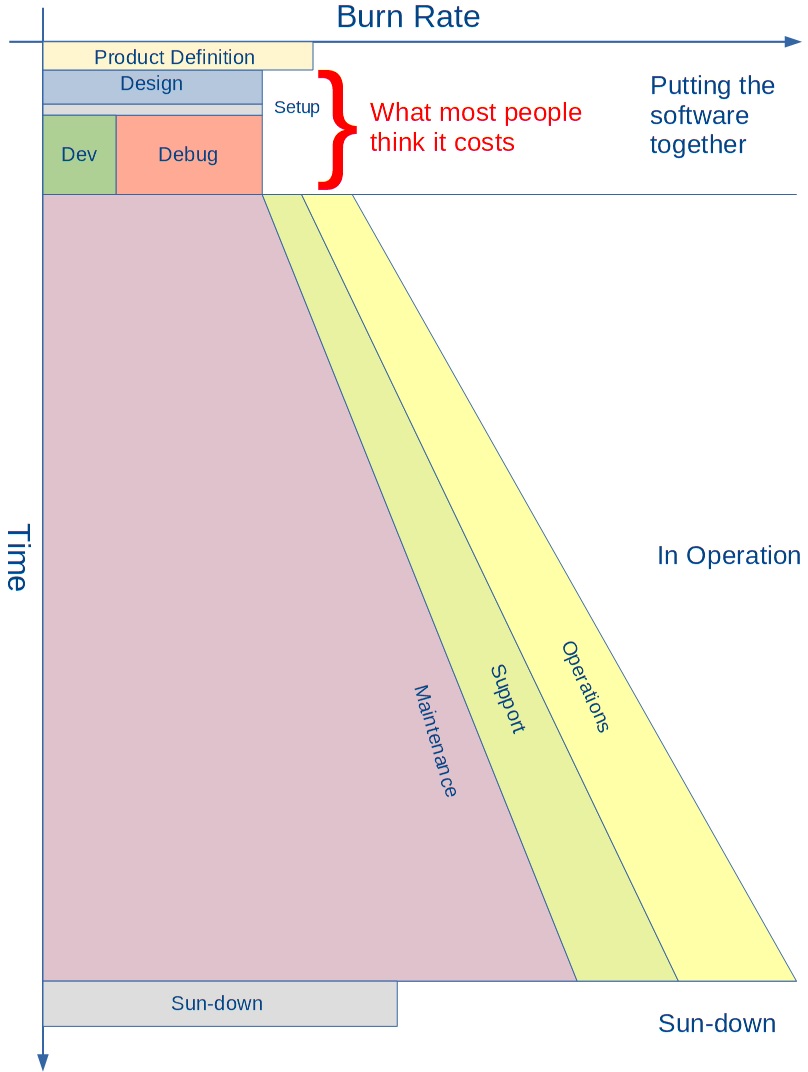
Cost structure at a glance
Based on this big picture, I want to leave you with three thoughts:
- Most people in the industry are missing most of the picture when it comes to software costs.
- Most of us in the industry make the wrong trade-offs when it comes to cost, because of our focus on development costs.
- Time pressure during development often causes us to optimize the cost of the small boxes at the expense of increasing the cost of the big ones.




